TL;DR: A universal methodology that extends short video diffusion models for efficient multi-text conditioned long video generation and editing.
Iron man is laying. Super long,
Video with smooth
Dog in the sun.
A car running on the beach.
Van Gogh
A girl is walking on the moon.
Leveraging large-scale image-text datasets and advancements in diffusion models, text-driven generative models have made remarkable strides in the field of image generation and editing. This study explores the potential of extending this text-based image strategy to the generation and editing of videos. Current methodologies, while innovative, are often confined to extremely short videos (typically less than 24 frames) and are limited to a single text condition. These constraints significantly limit their application given that real-world videos usually consist of multiple segments, each bearing different semantic information. To address this, we introduce a novel paradigm named as Gen-L-Video capable of generating and editing videos comprising hundreds of frames with diverse semantic segments, all while preserving content consistency, even under the confines of limited GPU resources. We have implemented three mainstream text-driven video generation and editing methodologies and extended them to accommodate longer videos imbued with a variety of semantic segments with our proposed paradigm. Our experimental outcomes reveal that our approach significantly broadens the generative and editing capabilities of video diffusion models, offering new possibilities for future research and applications.
Pretrained Text-to-Video (t2v): This involves training the diffusion model on a large-scale text-video paired dataset such as WebVid-10M. Typically, a temporal interaction module, like Temporal Attention, is added to the denoising model, fostering inter-frame information interaction to ensure frame consistency.
Tuning-free Text-to-Video (tuning-free t2v): This utilizes the pre-trained Text-to-Image model to generate and edit video frame-by-frame, while applying additional controls to maintain consistency across frames (for instance, copying and modifying the attention map, sparse casual attention etc.).
One-shot Tuning Text-to-Video (one-shot tuning t2v): By fine-tuning the pretrained text-to-image generation model using a single video instance, it's possible to generate videos with similar motions but different contents. Despite the extra training cost, one-shot tuning-based methods often offer more editing flexibility compared to tuning-free based methods.
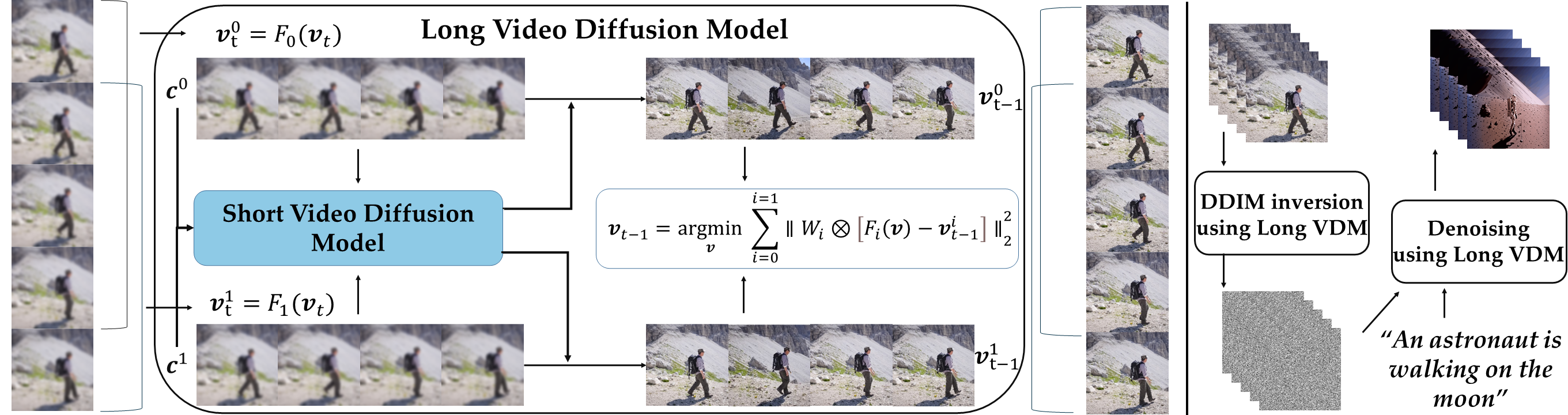
Unlike previous methods, we do not construct or train a long-video generator directly. Instead, we view a video as a collection of short video clips, each possessing independent semantic information. Hence, the generation of a long video can be seen as a concatenation of multiple short videos. While instead of simplistic division we perceive long videos as short video clips with temporal overlapping. We demonstrate that under certain conditions, the denoising path of a long video can be approximated by joint denoising of overlapping short videos in temporal domain. In particular, as depicted in the above figure, the noisy long video is initially mapped into multiple noisy short video clips via a designated function. Subsequently, existing off-the-shelf short video diffusion models can be employed to denoise these clips under the guidance of various text conditions. These denoised short videos are then merged and inverted back to a less noisy original long video. Essentially, this procedure establishes an abstract long video generator and editor without necessitating any additional training, enabling the generation and editing of videos of any length using established short video generation and editing methodologies.
Source Video of Demon Slayer
Boy ➜
Boy ➜
A man is boating, village ➜
A jeep car is running on the snow, sunny ➜
A jeep car is running on the beach, sunny ➜
Lion, grass, rainy ➜
Iron man is skiing in the snow➜
A man is surfing in the sea ➜
Source Video of Man Surfing
Mask of Man
Man ➜
SAM Segmentation Map
Control Map
Man ➜
Source Video of Eating Pizza
Mask of Pizza
Pizza ➜
Source Video of Girl in Water
Mask of Sunglasses
Sunglasses ➜
Pose Control Video
A man is playing tennis ➜
A man is playing tennis ➜
A man is playing tennis ➜
A man is playing tennis➜
A man is palying ➜
Depth Control Video
Cat in the sun ➜
Cat in the sun ➜
Astronaut riding a horse.
Isolated Generation.
Astronaut riding a horse.
Gen-L-Video.
Astronaut riding a horse.
Gen-L-Video.
Astronaut riding a horse, Painting.
Isolated Generation.
Astronaut riding a horse, Painting.
Gen-L-Video.
Astronaut riding a horse, Painting.
Gen-L-Video.
Hiking
Tower
Road Driving
Cow Walking
Raining
Skiing/Surfing
Win!
Road ➜
Road ➜
Jeep car ➜
Road ➜
Road ➜
Jeep car ➜
Worst!
Road ➜
Road ➜
Jeep car ➜
@misc{wang2023genlvideo,
title={Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising},
author={Fu-Yun Wang and Wenshuo Chen and Guanglu Song and Han-Jia Ye and Yu Liu and Hongsheng Li},
year={2023},
eprint={2305.18264},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
